DDiT: qué es, para qué sirve y cómo acelera los Diffusion Transformers
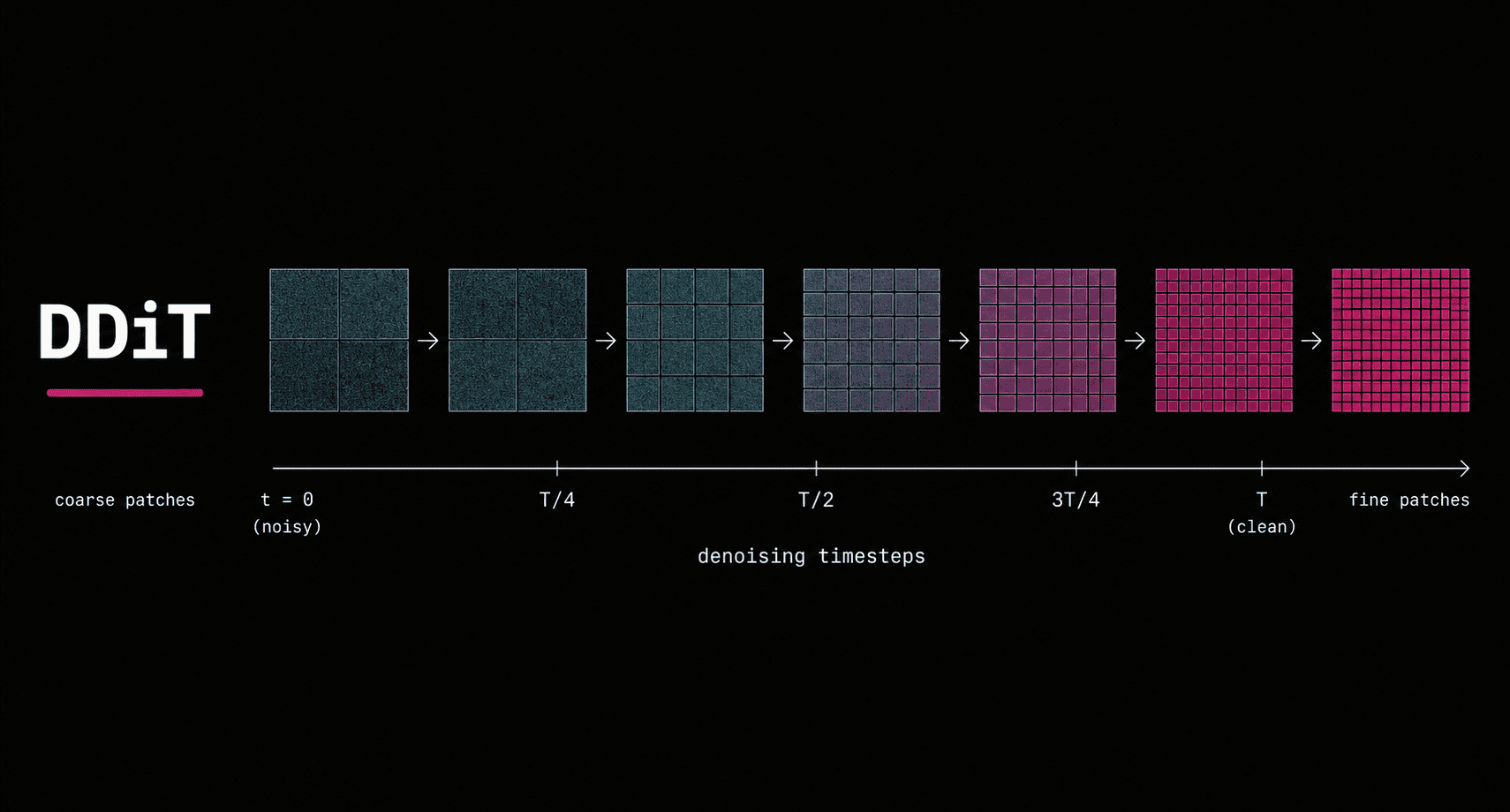
DDiT propone una idea muy concreta para acelerar Diffusion Transformers sin romper su lógica base: dejar de usar el mismo tamaño de parche durante todo el proceso de denoising. En lugar de mantener una tokenización fija de principio a fin, adapta la granularidad por timestep.
Los pasos tempranos usan parches más grandes para capturar estructura global con menos tokens. Los pasos tardíos usan parches pequeños para recuperar detalle fino. Ese cambio ataca uno de los cuellos de botella más caros del stack generativo actual.
Qué es DDiT y por qué importa
DDiT significa Dynamic Patch Scheduling for Efficient Diffusion Transformers. El trabajo apareció en arXiv en febrero de 2026 y plantea una optimización específica para modelos tipo DiT, donde el coste de atención depende fuertemente del número de tokens procesados en cada paso de inferencia.
La observación central del paper es razonable: en una difusión no todos los timesteps necesitan la misma resolución efectiva. Al principio interesa más fijar estructura, composición y forma global. Más tarde importa más el detalle local, la textura y el refinamiento fino. Procesar todos los pasos con el mismo tamaño de parche es una forma de sobregastar cómputo.
Tokenización fija durante todo el denoising
El modelo usa la misma granularidad en pasos donde no toda esa precisión aporta el mismo valor visual.
Tamaño de parche variable por timestep
Menos tokens cuando domina la estructura global y más tokens cuando toca recuperar detalle local.
Reducir latencia y coste sin degradación fuerte
El método busca una ganancia práctica de tiempo manteniendo calidad perceptual y alineamiento con el prompt.
Optimización accionable de inferencia
No intenta redefinir el modelo generativo; intenta gastar mejor el presupuesto computacional de cada sample.
DDiT no es un modelo nuevo de generación. Es una estrategia para hacer más eficiente la inferencia de modelos tipo DiT ya existentes, como FLUX.1-dev o Wan 2.1, combinando ajuste previo y scheduling dinámico en test-time.
Para qué sirve DDiT en IA generativa
Su utilidad principal es reducir el coste de inferencia en generación de imagen y vídeo. En modelos de difusión con backbone transformer, la cantidad de tokens pesa mucho en latencia, memoria y coste energético. Si puedes reducir tokens en ciertos pasos sin perder demasiado detalle, abres margen para tres cosas.
Primero, servir más peticiones con el mismo hardware. Segundo, generar con más rapidez en experiencias interactivas. Tercero, reinvertir parte del ahorro en más calidad, más frames o más muestras por prompt. En vídeo, la ganancia afecta directamente a throughput y a viabilidad real de despliegue.
-
T2I
Acelerar generación de imagen manteniendo métricas cercanas al baseline, sin degradar calidad solo reduciendo pasos de forma bruta.
-
T2V
Recortar tiempo en vídeo, donde el coste por sample es mucho más alto y cualquier ganancia puede liberar presupuesto para más frames o más iteración.
-
Producción
Reducir coste por inferencia en APIs, colas internas o pipelines batch donde el cuello de botella está en denoising.
-
Investigación
Explorar asignación adaptativa de cómputo en modelos generativos sin tener que entrenar un backbone completamente nuevo desde cero.
Cómo funciona DDiT: tokenización dinámica por timestep
La idea central es sencilla: el modelo no procesa todos los pasos del denoising con la misma granularidad. Para ciertos timesteps usa parches más grandes, lo que reduce el número de tokens de forma cuadrática y abarata la inferencia. Para otros pasos vuelve a parches pequeños, donde el modelo necesita más resolución para capturar detalle.
En el paper, esta lógica se conecta con una lectura del propio proceso de difusión. Los pasos tempranos son más útiles para composición global. Los tardíos son más útiles para textura y refinamiento local. Si el sistema detecta que el latente está cambiando de forma suave, puede permitirse una tokenización más gruesa. Si detecta regiones o fases con mayor complejidad, debe volver a granularidad fina.
Ese ajuste no se hace una sola vez por prompt, sino en cada paso. Por eso el valor de DDiT no está solo en soportar varios tamaños de parche, sino en decidir cuándo usar cada uno.
DDiT no reduce simplemente el número de pasos. Redistribuye la granularidad de cómputo a lo largo de esos pasos. Esa diferencia es lo que le permite competir con métodos agresivos de aceleración sin castigar tanto las métricas del output final.
Cómo adapta un DiT preentrenado a múltiples tamaños de parche
Aunque el scheduler en inferencia se presenta como training-free, la solución completa no es puramente plug-and-play. Para que un DiT preentrenado soporte nuevos tamaños de parche, el paper añade componentes de adaptación específicos.
Incorpora nuevas capas de patch-embedding y de-embedding para los tamaños extra, interpolación de embeddings posicionales y una señal explícita de patch-size embedding para que el modelo «sepa» qué granularidad está usando en cada forward. Además, incluye una rama LoRA de rango 32 en las capas feed-forward y un bloque residual adicional.
Esa ruta adaptativa se ajusta con una pérdida de distillation frente al modelo base congelado, de modo que la predicción de ruido del modelo adaptado se parezca a la del teacher original. En otras palabras: el scheduler por sí solo no basta. Antes hay que preparar el modelo para que opere bien con parches nuevos.
-
Nuevos patch-embedding y de-embedding
Se añaden ramas para tamaños mayores que el parche base, de forma que el modelo pueda patchificar y reconstruir con distintas granularidades.
-
Embeddings posicionales interpolados
El modelo reaprovecha la base preentrenada y adapta sus embeddings a la nueva resolución efectiva de tokens.
-
Patch-size embedding
Introduce una marca explícita para que la red condicione su comportamiento al tamaño de parche activo en cada paso.
-
LoRA + distillation
Permite adaptar el comportamiento sin reentrenar todo el backbone, manteniendo la salida cerca del modelo teacher congelado.
El scheduler dinámico: cómo decide el tamaño de parche
El scheduler de DDiT usa un proxy del «ritmo de cambio» del latente. El paper lo formula con diferencias finitas y presta especial atención a la tercera diferencia, que interpreta como una aceleración de la evolución del latente. Sobre esa señal, divide el tensor en parches candidatos, calcula dispersión interna y agrega el resultado con un percentil ρ para evitar que la media oculte regiones más complejas o texturadas.
La decisión conceptual es clara: elegir el parche más grande posible siempre que la señal agregada quede por debajo de un umbral τ. Si la complejidad supera ese umbral, el sistema vuelve a la granularidad fina. En sus experimentos, los autores reportan valores fijos de τ y ρ, pero la palanca útil del método está precisamente ahí: en cómo mover ese trade-off entre velocidad y fidelidad.
Este scheduler no necesita una red adicional que prediga la política. Usa una heurística sobre el propio latente, lo que mantiene el enfoque relativamente simple, pero deja abierta la puerta a mejoras futuras si alguien quiere sustituir la regla por una política aprendida.
No predice calidad final. Lo que hace es inferir cuánta granularidad necesita el paso actual observando cómo se está moviendo el latente. Es una política de asignación de cómputo, no un evaluador semántico del prompt.
Resultados en imagen y vídeo: qué mejora y qué no
En text-to-image, el paper toma FLUX-1.dev como baseline y reporta una reducción de latencia de 12,0 a 5,5 segundos por imagen con DDiT, equivalente a 2,18×, manteniendo FID y métricas de alineamiento cerca del baseline. Cuando lo combina con TeaCache, la latencia baja a 3,4 segundos y el speedup sube a 3,52×.
En text-to-video, usando Wan 2.1 1.3B, reporta speedups de hasta 3,2× con una caída moderada en VBench cuando combina DDiT con TeaCache. En producción, eso es relevante porque vídeo es precisamente donde el tiempo por sample y la fricción de iteración se vuelven más dolorosos.
| Método | Latencia | Speedup | Lectura rápida |
|---|---|---|---|
| FLUX-1.dev baseline | 12,0 s/imagen | 1,00× | Punto de referencia del paper. |
| DDiT | 5,5 s/imagen | 2,18× | Ganancia fuerte con degradación muy contenida en métricas reportadas. |
| DDiT + TeaCache | 3,4 s/imagen | 3,52× | Sinergia clara entre scheduling dinámico y caching. |
| Método | Speedup | VBench | Lectura rápida |
|---|---|---|---|
| Wan 2.1 baseline | 1,0× | 81,24 | Punto de partida del benchmark. |
| DDiT | 1,6× a 2,1× | 81,17 a 80,97 | Trade-off controlado entre velocidad y calidad agregada. |
| DDiT + TeaCache | 3,2× | 80,53 | Más velocidad, con caída algo mayor pero todavía moderada en el score reportado. |
El paper también incluye un user study donde DDiT sale preferido frente al baseline en una proporción relevante de comparaciones. Esa parte no sustituye a la evaluación cuantitativa, pero apunta a algo interesante: acelerar no implica necesariamente una percepción visual peor en todos los casos.
Cómo se usaría DDiT en un stack real de IA
Si alguien quiere llevar DDiT a un pipeline real, no basta con copiar una heurística. Hay que intervenir el modelo base para soportar patch sizes adicionales, hacer el ajuste LoRA con distillation y después desplegar el scheduler en inferencia. En imagen, el candidato natural del paper es FLUX. En vídeo, Wan 2.1 es especialmente interesante por su ecosistema público y su licencia Apache-2.0.
La combinación con TeaCache parece una de las rutas más naturales, porque el propio paper muestra sinergia entre ambos enfoques. DDiT redistribuye granularidad. TeaCache reutiliza o evita recomputación. Son dos palancas distintas sobre el mismo cuello de botella.
-
Elegir modelo base compatible
FLUX para T2I o Wan 2.1 para T2V son los ejemplos del paper, pero la licencia del peso elegido importa tanto como la arquitectura.
-
Modificar el modelo para multipatch
Añadir embeddings y rutas necesarias para operar con 2p y 4p sin romper la estructura original del backbone.
-
Ajustar con distillation
Entrenar la rama adaptativa para que la predicción del modelo extendido se mantenga cerca del teacher base congelado.
-
Desplegar el scheduler en inferencia
Configurar τ y ρ como parte del presupuesto de cómputo y del objetivo de calidad del producto.
-
Medir con métricas y evaluación humana
No quedarse solo en FID, CLIP o VBench; en producto conviene añadir latencia p50/p95, VRAM, throughput y revisión visual real.
Impacto en IA generativa, búsqueda visual y RAG multimodal
El impacto más directo de DDiT está en sistemas generativos, pero su efecto no termina ahí. Si generar candidatos visuales o frames se vuelve más barato, también se abarata una parte de los workflows que usan generación como soporte de recuperación, prototipado, augmentación de datos o explicación multimodal.
Lo que cambia es el coste de producir imágenes o vídeos sintéticos dentro de pipelines donde esos assets se usan como candidatos, como material auxiliar o como evidencia generada bajo demanda. En contextos de RAG multimodal, eso puede importar cuando una aplicación necesita crear visualizaciones rápidas bajo un SLA exigente.
-
Producto
Más iteración por usuario o menor coste por request en generadores de imagen y vídeo.
-
Infraestructura
Más throughput con el mismo presupuesto de GPU, siempre que el resto del pipeline no se convierta en el nuevo cuello de botella.
-
RAG
Posible reducción del coste cuando una aplicación necesita generar evidencia visual o thumbnails sintéticos bajo demanda.
-
Investigación
Abre una línea clara de trabajo sobre asignación adaptativa de cómputo en DiTs, tanto temporal como espacial.
Limitaciones, reproducibilidad y licencias: la parte que más condiciona negocio
La propuesta es potente, pero tiene varias fricciones reales. La primera es la reproducibilidad. A fecha de esta revisión no aparece un repositorio oficial claramente publicado junto al paper, ni checkpoints propios de DDiT identificables en las fuentes primarias revisadas. Eso limita mucho la validación externa y deja al lector con una implementación descrita, pero no con una base canónica fácil de ejecutar.
La segunda fricción es operativa. El paper reporta tiempos de latencia, pero no deja tan explícitos como sería deseable el hardware exacto, la precisión numérica, el batch size o el stack completo de optimización. En inferencia generativa, pequeñas decisiones del entorno cambian bastante el tiempo final.
La tercera es legal. FLUX.1-dev tiene una licencia no comercial para los pesos, mientras que FLUX.1-schnell aparece con Apache-2.0 en el repositorio oficial. Wan 2.1 publica su suite bajo Apache-2.0. Esa diferencia puede pesar tanto como el speedup en una decisión de producción.
DDiT es una idea muy accionable desde el punto de vista técnico, pero todavía no es una pieza «drop-in» con trazabilidad pública equivalente a la que sí tienen TeaCache o Wan 2.1.
Qué haría hoy si quisiera probar DDiT con criterio
La recomendación más razonable es tratar DDiT como una línea de ingeniería, no como una feature cerrada lista para integrar. Si el objetivo es investigar aceleración en DiTs con impacto real en latencia, merece la pena. Si el objetivo es desplegar en producción rápido, la ausencia de una implementación canónica pública complica bastante el camino.
El mejor experimento reproducible sería implementarlo sobre un stack abierto y bien instrumentado, declarar hardware, precisión, throughput, VRAM y métricas de calidad, y comparar al menos contra baseline, reducción de steps, TeaCache y una combinación de ambos. En vídeo, Wan 2.1 parece el punto de partida más pragmático por su ecosistema y licencia.
Trátalo como proyecto de ingeniería
No hay suficiente empaquetado público como para considerarlo una mejora plug-and-play en marzo de 2026.
Probar sobre Wan 2.1
Pro: ecosistema abierto y licencia Apache-2.0. Contra: sigue exigiendo implementación y validación propias.
Explorar combinación con TeaCache
Pro: el paper ya sugiere sinergia clara. Contra: añade otra capa de complejidad experimental.
Esperar implementación pública
Pro: menos coste inicial. Contra: dependes de que la comunidad o los autores publiquen una versión canónica.
Fuentes y enlaces prioritarios
Para que el contenido no dependa solo del resumen del paper, conviene revisar directamente las fuentes principales del ecosistema que rodea a DDiT:
- DDiT — preprint en arXiv / ficha pública → Ver paper
- FLUX — repositorio oficial y licencias de pesos → Ver repositorio · Ver licencia de FLUX.1-dev
- Wan 2.1 — suite abierta para vídeo → Ver organización · Ver descripción pública y licencia
- TeaCache — referencia clave de aceleración complementaria → Ver paper
- TaylorSeer — comparación de aceleración por forecasting → Ver paper
- T2I-2M — dataset usado para ajuste en imagen → Ver dataset
- Vchitect-T2V-DataVerse — prompts y datos de vídeo → Ver dataset
- ImageReward y CLIP — métricas relacionadas con evaluación → Ver ImageReward · Ver CLIP
Comparativa de rendimiento y calidad
Resumen de los principales métodos de aceleración en Diffusion Transformers comparando latencia, velocidad relativa y métricas de calidad visual reportadas en las fuentes analizadas.
| Método | Modelo | Speedup | Latencia | Calidad | Licencia |
|---|---|---|---|---|---|
| DDiT | FLUX.1 dev | 2,18× | 5,5 s | FID 33,42 · CLIP 0,317 | No comercial |
| DDiT + TeaCache | FLUX.1 dev | 3,52× | 3,4 s | FID 33,60 · CLIP 0,315 | No comercial |
| DDiT (τ=0.001) | Wan 2.1 | 2,1× | — | VBench 80,97 | Apache-2.0 |
| DDiT + TeaCache | Wan 2.1 | 3,2× | — | VBench 80,53 | Apache-2.0 |
| TaylorSeer | FLUX.1 dev | 3,43× | 3,5 s | FID 35,02 | No comercial |
| TeaCache | FLUX.1 dev | 2,25× | 5,33 s | FID 35,57 | No comercial |
| Baseline | FLUX.1 dev | 1,00× | 12,0 s | FID 33,07 | No comercial |
| Baseline | Wan 2.1 | 1,0× | — | VBench 81,24 | Apache-2.0 |
DDiT reduce significativamente la latencia en Diffusion Transformers manteniendo métricas cercanas al baseline. En imagen destaca por preservar FID y alineamiento, mientras que en vídeo ofrece mejoras claras de rendimiento sobre Wan 2.1 con una caída moderada en VBench.
