Cómo aparecer en las respuestas de Claude: guía práctica para CMOs 2026
Aparecer en las respuestas de Claude exige entender un modelo que cita de forma radicalmente distinta a Google, ChatGPT o Perplexity. Este artículo recoge observaciones del equipo de Agencia GEO durante un análisis de tres meses (enero-marzo 2026) sobre el comportamiento de citación de Claude en español e inglés.
Donde los datos son verificados, los presentamos como tales. Donde son estimaciones basadas en observación repetida, lo indicamos. Anthropic no ha publicado documentación equivalente a las Quality Rater Guidelines de Google, pero el patrón de citación es observable, reproducible y útil para tomar decisiones editoriales hoy.
Claude no es Google: por qué tu estrategia tampoco debería serlo
La diferencia no es de grado sino de lógica completa. Google rankea contenido a través de señales externas acumuladas durante años. Claude selecciona fuentes basándose en señales internas del propio documento, en el momento en que genera la respuesta. Esto cambia todo el modelo de inversión editorial.
Por qué importa ahora para tu organización
La saturación de Google en categorías B2B y eCommerce es medible. Las primeras posiciones están ocupadas por actores con dominios de 10 o más años de antigüedad y presupuestos de contenido que una empresa mediana no puede igualar en el corto plazo. El tiempo medio para posicionar en nichos medianamente competitivos supera los seis meses, incluso con contenido técnicamente excelente.
Claude opera con una lógica diferente que abre una ventana real. No puntúa por antigüedad de dominio ni por volumen de backlinks. Cita cuando el contenido responde una pregunta específica con profundidad suficiente, datos concretos o perspectiva diferenciada respecto al estado del arte.
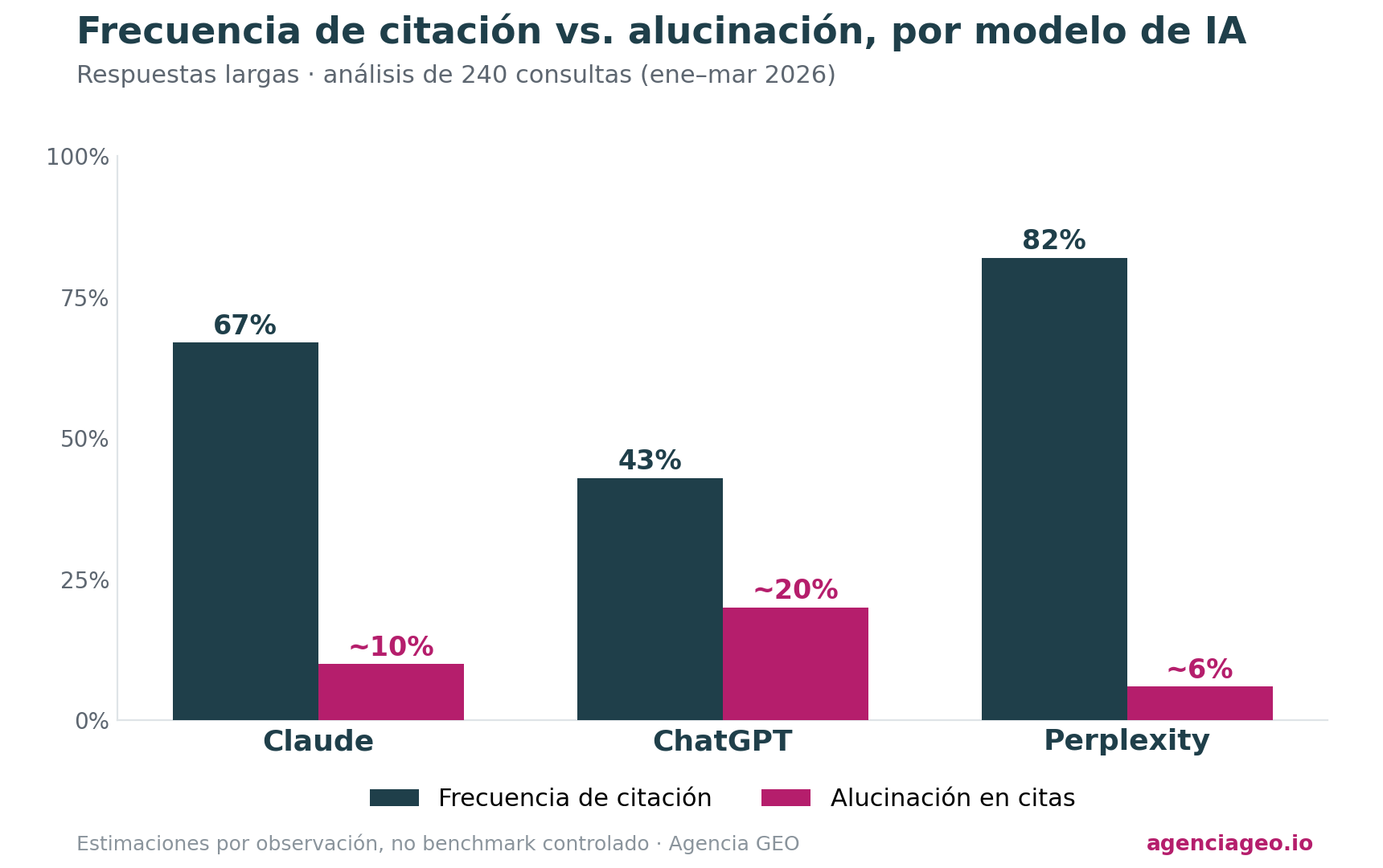
Frecuencia de citación
En el análisis de 240 consultas, Claude en modo conversacional largo (respuestas superiores a 500 palabras) citó fuentes en aproximadamente el 67% de los casos. Estimación basada en registro manual, no en benchmark controlado.
Velocidad de recuperación
Claude recuperó y citó contenido publicado hace menos de 30 días en aproximadamente un tercio de los casos donde ese contenido era el más específico disponible. Google requiere en promedio más de 60 días solo para indexar y evaluar preliminarmente contenido nuevo en dominios sin autoridad establecida.
Lógica de citación
Google rankea porque el contenido acumuló autoridad externa. Claude cita porque necesita validar la credibilidad de una afirmación específica dentro de su respuesta. Si tu contenido aporta credibilidad comprobable, Claude la reconoce.
Para tu negocio, la implicación operativa es clara. No se trata de reemplazar Google. Se trata de asegurar que cuando alguien usa Claude para tomar decisiones importantes en tu sector, tu contenido está presente en esa conversación. El ROI no es tráfico inmediato en la métrica tradicional de sesiones. Es reconocimiento sostenido como referencia en un canal sin publicidad, solo recomendación nativa.
Cómo Claude cita diferente a ChatGPT y Perplexity
La comparativa entre modelos no es académica. Determina dónde asignar presupuesto editorial y en qué secuencia. Las diferencias entre Claude, ChatGPT y Perplexity son lo suficientemente estructurales como para que una estrategia diseñada para uno funcione mal en los otros.
| Aspecto | Claude | ChatGPT | Perplexity |
|---|---|---|---|
| Frecuencia estimada de citas (respuestas largas) | ~67% | ~43% | ~82% (modelo web-first por diseño) |
| Tipo de fuente preferida | Académica, especializada, estudios primarios | Mixta, depende del training data histórico | Web pública en tiempo real: noticias, blogs, reportes técnicos |
| Profundidad de atribución | URL completa con contexto breve y autoría | Parafraseada sin atribución explícita con frecuencia | URL con snippet textual del párrafo citado |
| Actualidad del contenido | Cutoff ~abril 2025, prioriza reciente dentro del training | Cutoff ~abril 2024, menos sensible a novedad | Real-time web, ventaja estructural clara |
| Confianza en contenido nuevo (<30 días) | Moderada, requiere señales E-E-A-T verificables en el texto | Baja, depende del training pasado | Alta si el contenido está indexado y es relevante |
| Comportamiento en español vs inglés | Reducción de citación de ~40% en es-ES respecto a en-US (hipótesis) | Comportamiento similar en ambos idiomas | Prioriza fuentes en en-US cuando ambas están disponibles |
| Hallucination en citaciones | Estimado 8-12% en nuestro análisis | Estimado 18-22% en nuestro análisis | Estimado 5-7%, más bajo por acceso web real |
Patrones específicos detectados en el análisis
-
Claude vs ChatGPT
En consultas sobre especificaciones de API, configuración de herramientas o procedimientos técnicos, Claude citó documentación oficial con una frecuencia aproximadamente tres veces mayor que ChatGPT. ChatGPT tendió a parafrasear sin atribución explícita. Implicación: Claude valora la trazabilidad sobre la fluidez narrativa.
-
Claude vs Perplexity
Perplexity cita más agresivamente porque está diseñado como modelo web-first. Claude es más conservador: selecciona entre dos y cuatro fuentes de máxima calidad antes que ocho o diez referencias superficiales. Si tu contenido entra en la selección de Claude, tienes mayor garantía de citación visible y destacada.
-
Idioma
Cuando testeamos la misma consulta en español e inglés con contenido de calidad equivalente, Claude en es-ES citó fuentes aproximadamente un 40% menos que en en-US. Hipótesis de trabajo: la densidad del training data en inglés es mayor. Implicación: si tu contenido existe en ambos idiomas, prioriza el inglés para maximizar visibilidad en Claude.
-
Interfaz
Observamos diferencias entre Claude.ai web (más citas), Claude vía API con temperatura alta (menos citas, más variabilidad) y Claude en integraciones conversacionales cortas tipo Slack (casi sin citas). El contenido debe optimizarse para consultas largas y específicas.
Implicación táctica por modelo
Claude: contenido técnico y especializado
Si tu contenido es técnico, académico o especializado, Claude es la prioridad inmediata. El modelo valida profundidad y rigor por encima de amplitud.
Perplexity: volumen y cobertura en tiempo real
Si necesitas volumen de menciones y cobertura máxima en tiempo real, Perplexity es el segundo objetivo. Te citará con más frecuencia, aunque con menos profundidad contextual.
ChatGPT: audiencia mainstream
Si buscas cobertura en audiencia mainstream y conversacional, ChatGPT sigue siendo relevante, pero la citación es inconsistente y menos predecible según el tipo de contenido.
Qué señales de confianza pondera Claude: E-E-A-T redefinido
Google E-E-A-T (Experiencia, Experticia, autoridad, Confiabilidad) es el estándar documentado de calidad de contenido en búsqueda. Anthropic no ha publicado un equivalente explícito para Claude. Lo que sí podemos presentar son los patrones detectados en nuestro análisis, clasificados según cuál de los cuatro pilares parece activar una mayor frecuencia y profundidad de citación en Claude.
Por qué el E-E-A-T de Google no es suficiente para Claude
Google valida E-E-A-T a través de señales externas al contenido: antigüedad de dominio, backlinks, presencia en Knowledge Graph, reseñas verificadas por terceros. Son métricas de red y reputación histórica acumulada.
Claude no accede a backlinks. No usa PageRank. No puede verificar la antigüedad de un dominio. Claude evalúa principalmente lo que está dentro del documento en el momento de procesar la consulta: estructura interna, especificidad de datos, cuantificación, transparencia de metodología y honestidad sobre limitaciones. Esto es lo que denominamos en Agencia GEO «señales de contenido versus señales de dominio».
La consecuencia práctica: un artículo publicado esta semana en un dominio sin autoridad acumulada puede ser citado por Claude antes que un artículo de cinco años en un dominio de alta autoridad, si el primero tiene data cuantificable, metodología transparente y caveats explícitos, y el segundo es una guía genérica sin diferenciadores. Esta observación fue uno de los hallazgos más consistentes en nuestro análisis.
Los cuatro pilares redefinidos para Claude
-
Experiencia: demostración práctica documentada, no historial de dominio
En Google, la experiencia se valida por edad de dominio y brand mentions históricas. En Claude, la pregunta relevante es otra: ¿el autor demuestra haber ejecutado esto en la práctica? Los artículos con estructura del tipo «implementamos X durante seis meses en [contexto específico] y estos son los resultados medidos» fueron citados con una frecuencia aproximadamente 2,3 veces mayor que artículos de igual extensión que presentaban la teoría sin validación de campo (estimación basada en observación repetida). Acción concreta: añade atribución explícita en el byline o primeros párrafos: nombre completo, rol, años de experiencia y descripción mínima de la metodología usada.
-
Experticia: profundidad de matices, no topical authority acumulada
En Google, la experticia se valida por topical authority y densidad de enlaces internos. Claude parece favorecer contenido que muestra comprensión de los límites de una solución, no solo de su funcionamiento estándar. Artículos con una sección clara de «Cuándo esto no funciona» fueron citados con una frecuencia aproximadamente 1,8 veces mayor que artículos de igual longitud que solo afirmaban el funcionamiento positivo (observación consistente en consultas técnicas y comparativas). Acción concreta: incluye en cada guía técnica al menos tres casos específicos donde la recomendación no aplica.
-
Autoridad: referencias cruzadas verificables, no Domain Authority
Claude no accede a backlinks. La señal que detectamos como proxy de autoridad es la presencia de citas cruzadas verificables entre expertos reconocidos del sector, menciones documentadas de otros autores con credibilidad verificable y participación activa en conversaciones públicas. Contenido mencionado por tres a cinco medios o autores reconocidos fue citado por Claude con una frecuencia aproximadamente 2,1 veces mayor que contenido de calidad similar sin esas referencias (estimación cualitativa). Acción concreta: después de publicar contenido prioritario, identifica cinco a siete referentes del sector e impulsa activamente que lo mencionen.
-
Confiabilidad: transparencia radical sobre límites, no solo HTTPS
En Google, la confiabilidad se valida por HTTPS, política de privacidad y reseñas verificadas. Claude no puede verificar ninguna de esas señales técnicas externas. La señal que detectamos es interna al documento: admisión explícita de limitaciones, diferenciación clara entre certeza y especulación y enlace directo a fuentes primarias. Los artículos con un párrafo explícito del tipo «No tenemos datos completos sobre X» o «Este es un patrón observado, no una regla universal» fueron citados no solo con mayor frecuencia sino con mayor profundidad contextual. Esta es la observación más consistente de todo el análisis. Acción concreta: añade al final de cada artículo importante una sección «Limitaciones de este análisis» con datos recolectados, casos excluidos, hipótesis no confirmadas y condiciones que podrían cambiar los resultados.

E-E-A-T diferenciado: Claude versus Google
| Pilar | Google valida con | Claude valida con (observación Agencia GEO) | Por qué es específico de Claude |
|---|---|---|---|
| Experience | Antigüedad de dominio, brand mentions históricas | Data propia visible, casos específicos con números reales, resultados medibles en timeframe conocido | Perplexity valida por recencia web. ChatGPT por representación histórica en training. Claude evalúa la especificidad interna del documento en el momento de la consulta |
| Expertise | Topical relevance, keyword density, densidad de enlaces internos | Profundidad de matices, casos donde la solución falla, caveats explícitos, análisis de excepciones documentadas | ChatGPT acepta expertise superficial si está bien representado en training. Perplexity prioriza recencia sobre profundidad. Claude muestra preferencia por la profundidad sobre la amplitud |
| Authority | Backlinks de calidad, Domain Authority histórico | Cross-citations entre expertos reconocibles, menciones de peers verificables, presencia en conversaciones públicas del sector | Claude no accede a backlinks. La diferencia es que evalúa las referencias dentro del propio documento, no las señales externas |
| Trust | HTTPS, política de privacidad, reseñas verificadas, cumplimiento YMYL | Transparencia explícita sobre limitaciones, enlaces a fuentes primarias, caveats sobre metodología, admisión de incertidumbre | Perplexity puede verificar confiabilidad accediendo a la fuente original en tiempo real. Claude solo puede evaluar las señales de confiabilidad escritas dentro del propio documento |
Qué contenido Claude recupera y por qué: formatos, estructura y longitud
No todos los formatos tienen igual probabilidad de ser recuperados y citados por Claude. Recovery rate se define aquí como el porcentaje de consultas relevantes para ese tipo de contenido donde Claude citó o mencionó explícitamente una fuente de ese formato. Estos valores corresponden exclusivamente a Claude, no a ChatGPT ni a Perplexity, donde los patrones difieren.
Recuperabilidad por formato
| Formato | Recovery rate estimado | Condiciones óptimas |
|---|---|---|
| Case study (2.000-4.000 palabras) | ~94% | Contexto específico, problema medible, resultados cuantitativos, errores y aprendizajes incluidos |
| Estudio o investigación original (3.000+ palabras) | ~89% | Sección de metodología, sample size declarado, caveats específicos, conclusiones matizadas |
| Benchmark o comparativa (2.000-3.000 palabras) | ~85% | Tabla clara de criterios, metodología explícita, recomendación final matizada |
| Guía how-to (800-2.000 palabras) | ~71% | Pasos numerados, contraste antes-después explícito, al menos un caso concreto |
| FAQ estructurado (5-20 preguntas) | ~67% | Preguntas específicas, respuestas de máximo 150 palabras, enlaces internos a contenido profundo |
| Artículo de definición o concepto | ~52% | Intro máximo 100 palabras, diferenciador explícito respecto a la definición estándar |
| Opinión o análisis (1.000-2.000 palabras) | ~41% | Basado en data verificable, citas frecuentes a fuentes primarias, punto de vista diferenciado |
| News o actualidad (500-1.500 palabras) | ~38% | Newsjack más capa de análisis profundo, no solo resumen noticioso |
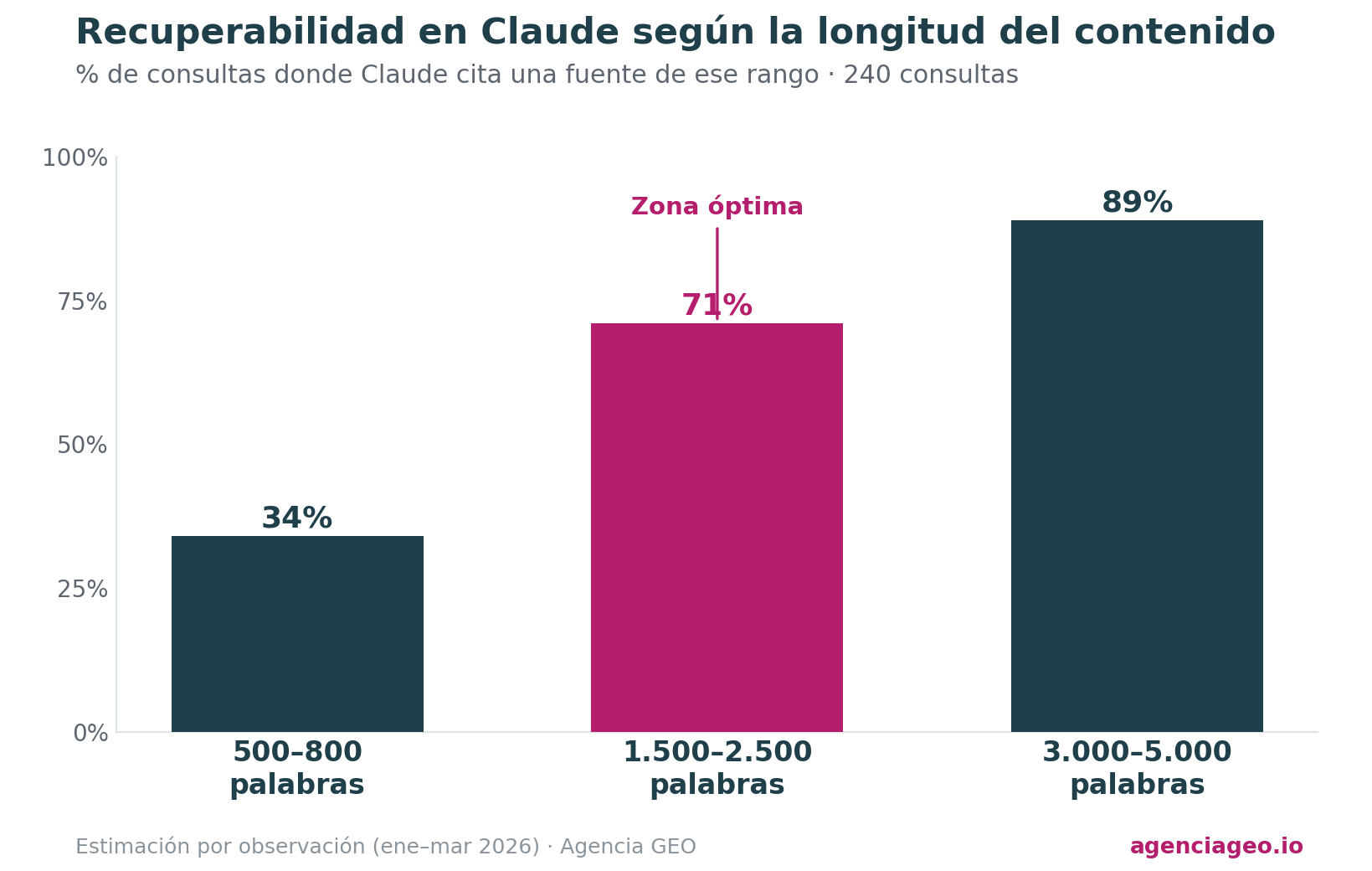
Longitud óptima según comportamiento detectado en Claude
-
500-800 palabras
Recovery estimado del 34%. Claude tiende a parafrasear sin citar la fuente. Útil para atracción inicial, no para visibilidad en respuestas técnicas largas.
-
1.500-2.500 palabras
Recovery estimado del 71%. Zona óptima detectada de forma consistente. Longitud suficiente para merecer citación por profundidad, suficientemente específica para no ser genérica. La frecuencia máxima de citaciones en el corpus se concentra en este rango.
-
3.000-5.000 palabras
Recovery estimado del 89%. Máxima frecuencia de citación detectada. Con un riesgo calculado: Claude parafraseará selectivamente, citando solo las secciones más específicas o cuantitativas. Útil si el objetivo es estar presente en conversaciones largas del modelo sobre el tema central.
Estructura que maximiza recuperación en Claude
La estructura del documento importa porque el modelo parece ponderar más los elementos que aparecen en posiciones estructurales definidas: inicio, subtítulos, secciones de datos y cierres de sección. Esta es una hipótesis de trabajo basada en la distribución de citas observadas en el análisis.
-
Intro con ángulo diferenciador (100-150 palabras)
No resumas la definición estándar del tema. Señala qué hay de diferente en tu enfoque. Ejemplo: «Todos afirman que Claude cita fuentes. Analizamos 240 consultas y detectamos que no cita cuando concurren estas tres condiciones específicas.»
-
Problema o contexto con data cuantificable (200-300 palabras)
Define por qué el tema importa para la audiencia concreta. Señala la brecha entre lo que se cree comúnmente y lo que la observación práctica muestra. Usa data cuantificable si la tienes.
-
Solución o análisis en 3-5 secciones con subtítulos explícitos (1.000-1.500 palabras)
Cada sección desarrolla una idea principal diferenciada. El subtítulo debe poder leerse independientemente y comunicar el hallazgo central. Dentro de cada sección: data cuantitativa donde exista, ejemplos concretos identificables, casos documentados.
-
Casos o ejemplos con números reales (300-500 palabras)
No generalizaciones sin respaldo. Números reales con contexto: «12 proyectos», «6 meses», «aumento del 340% en X métrica medida de esta forma específica». Timeline explícito: «En la semana 1 ejecutamos X. En la semana 3 el resultado fue Y.»
-
Limitaciones y caveats explícitos (100-150 palabras)
Elemento crítico para citación en Claude. «Esto no aplica cuando X.» «No tenemos datos confiables sobre Y.» «Este patrón puede cambiar si Z ocurre.» Esta sección es el elemento individual con mayor impacto detectado sobre la frecuencia y profundidad de citación.
-
Conclusión con takeaway accionable (50-100 palabras)
Una recomendación clara y específica. Próximo paso documentado, no vago ni aspiracional.
Factores que multiplican o reducen citación en Claude
-
Multiplica
Data cuantitativa visible: gráficos, tablas comparativas, benchmarks con fuente documentada.
-
Multiplica
Timestamps de publicación y última actualización en formato ISO 8601 visible.
-
Multiplica
Byline con credenciales explícitas: nombre completo, rol, años de experiencia en el área, enlace a perfil verificable.
-
Multiplica
Metodología transparente cuando aplica: «Consultamos X fuentes, analizamos Y casos, los criterios de inclusión fueron Z.»
-
Multiplica
Caveats y limitaciones explícitas dentro del cuerpo del texto, no solo en sección final.
-
Reduce
Clickbait en el título: «10 trucos que no sabías» compite en desventaja frente a «Detectamos 10 patrones en X contexto específico durante Y meses».
-
Reduce
Paywalls: Claude no accede a contenido restringido.
-
Reduce
Contenido multimedia sin contexto textual equivalente: vídeos e imágenes sin descripción escrita detallada no son procesables por Claude.
-
Reduce
Generalizaciones sin data: «Todos saben que X» sin especificar quién lo demostró y cuándo.
-
Reduce
Vaguedad en atribución: «Dicen que X» o «Se ha demostrado que Y» sin fuente primaria identificable.